Working with regular expressions
Introduction to regular expressions in Enso
Regular expressions, often abbreviated as "regex" or "regexp", are powerful tools for searching and manipulating text. They might seem a bit daunting at first, but they are incredibly useful once you get the hang of them. In essence, a regular expression is a search pattern. This pattern can be used to find specific strings within text, validate data formats, or even perform complex text replacements.
Why use regular expressions?
As a data analyst, you’ve likely encountered scenarios where you need to clean or manipulate text data. While you have many text processing functions at your disposal, regular expressions allow you to perform more complex operations in a much more efficient manner. Here are some examples where regular expressions can be a game-changer:
- Validating email addresses: Ensure that email addresses in your dataset follow a proper format.
- Extracting specific information: Pull out phone numbers, dates, or any specific patterns from a block of text.
- Replacing patterns: Quickly replace certain patterns of text, such as converting dates from “MM/DD/YYYY” format to “YYYY-MM-DD”.
- Splitting text: Divide text based on complex delimiters, such as splitting a full name into first and last names when the delimiter might vary.
In this tutorial, we’ll dive into how to use regular expressions in Enso, helping you leverage their power to streamline your data processing tasks. Don’t worry if this seems complex; we’ll guide you step by step through each example.
Your first regular expression
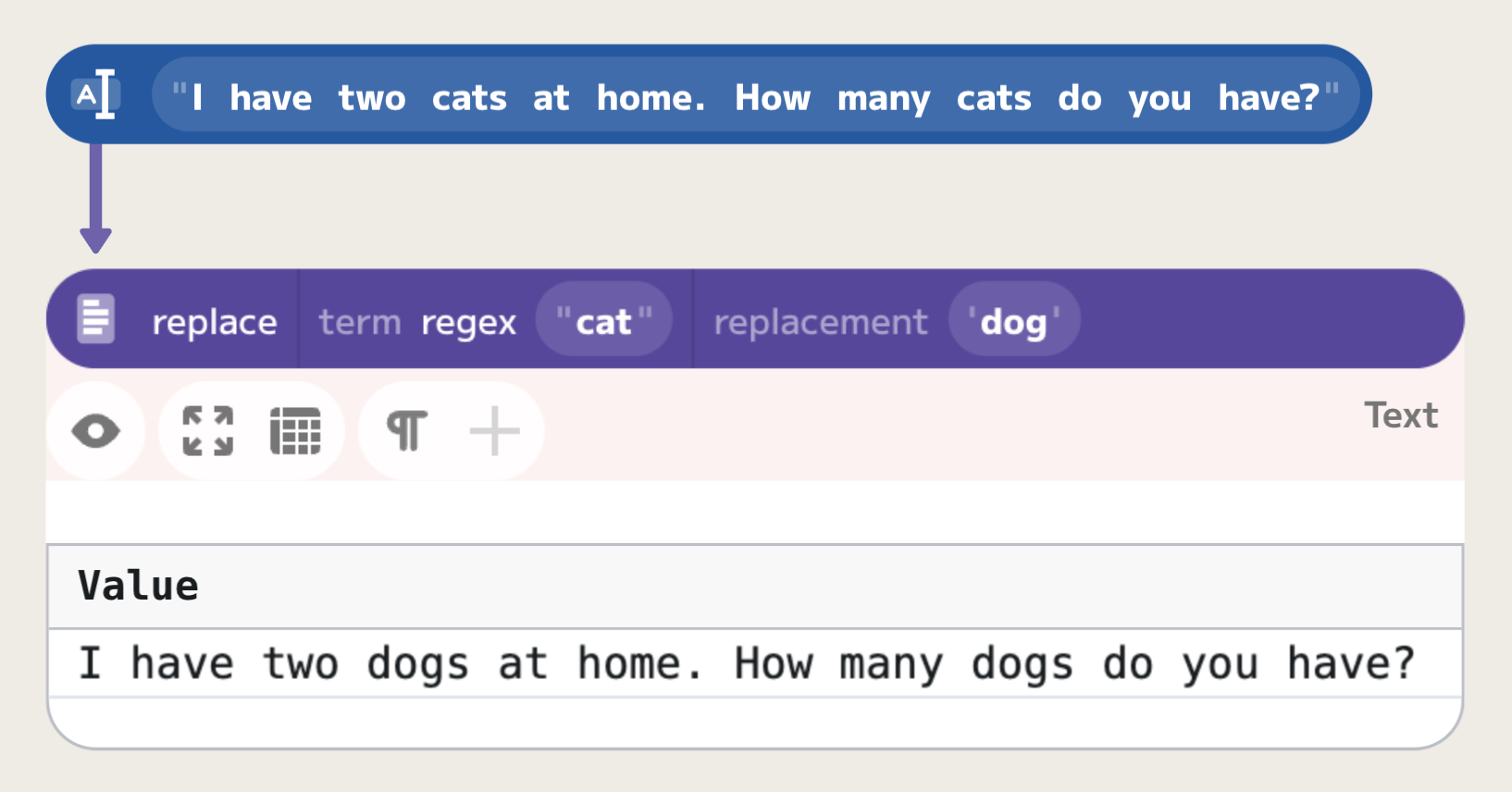
The simplest regular expression is just a pattern for a given text. For example,
if you want to replace all occurences of a word "cat" in a text, the regular
expression you can use is simply "cat". The simplest way to test it in Enso is
to use the replace method:
Matching beginning and end of text
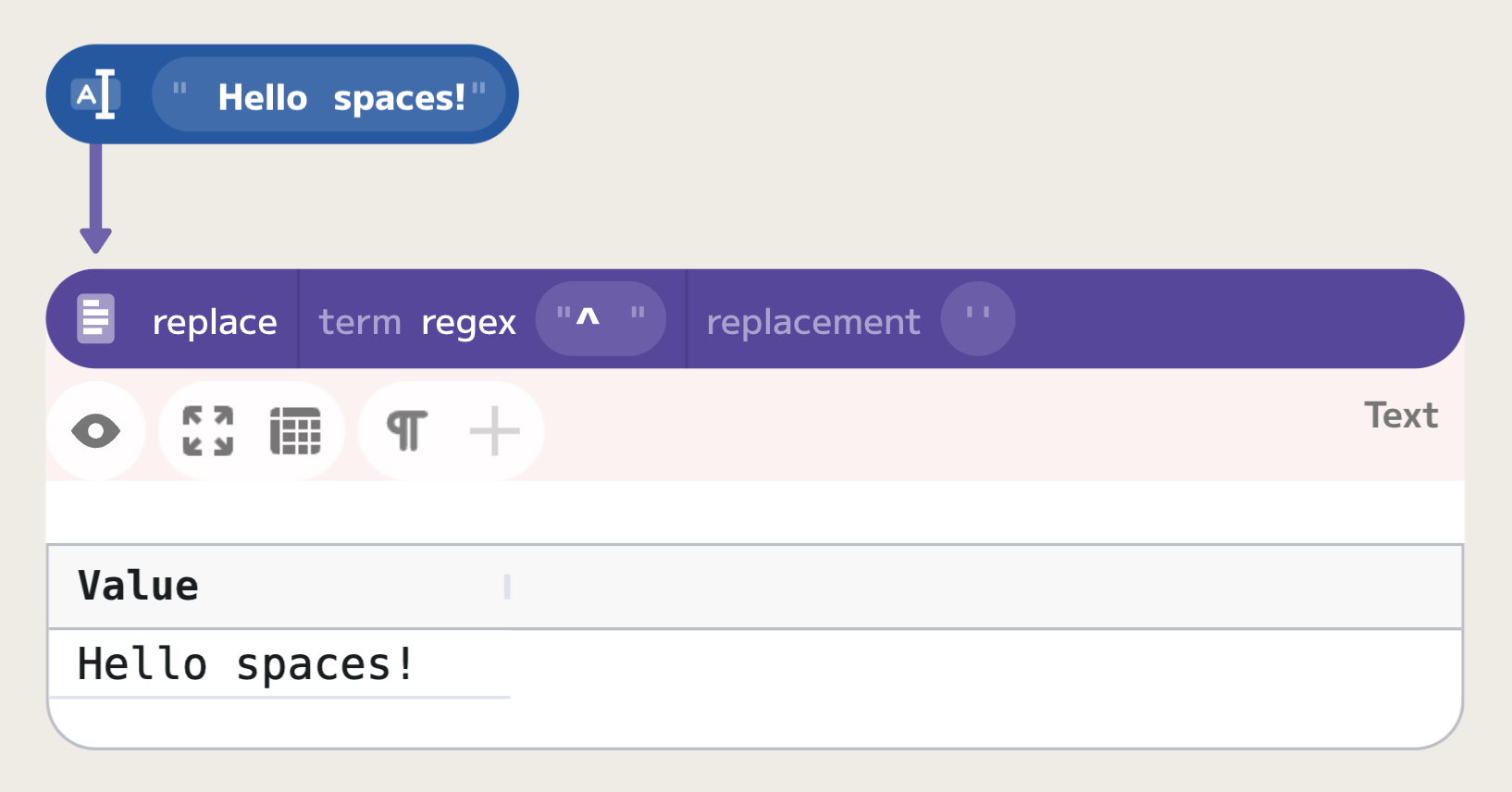
In regular expressions, the ^ symbol is used to match the beginning of a line,
and the $ symbol is used to match the end of a line. For example, if we want
to trim leading space in a line, we can use the "^ " regular expression:
Escape characters
As you've seen, some symbols in regular expressions have special meanings. If
you want to match these symbols literally, you need to escape them. In Enso, you
can do this by using the backslash \ character. For example, if you want to
match a dot the ^ character and not use it as an indicator of the beginning of
a line, you can use the regular expression "\^". This rule applies to all
special symbols that you will see in this tutorial.
Repetitions
The above example would not give us the correct result if the input sentence would start with more than one space. The regular expression we used matches just a single space at the begging of the line. In order to match multiple occurences, you can use one of the following symbols:
*: Matches 0 or more occurences.+: Matches 1 or more occurences.{n}: Matches exactlynoccurences.{n,}: Matches at leastnoccurences.{n,m}: Matches betweennandmoccurences.
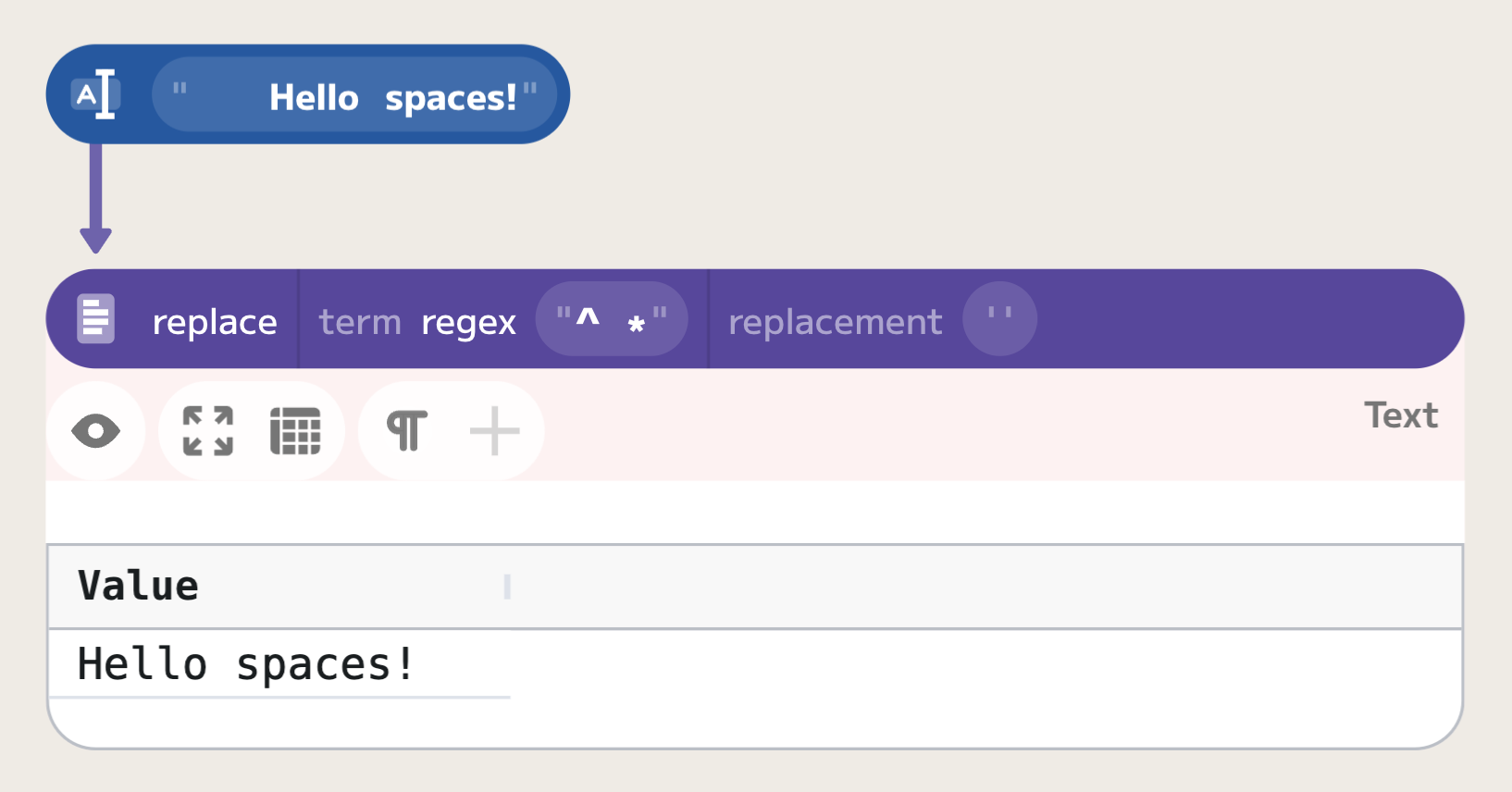
For example, if we want to trim all leading spaces in a line, we can use the
"^ *" regular expression:
Please note that the * and + symbols are applied to the preceding character
only. For example, regular expression "ab*" matches "a", "ab", "abb",
"abbb", and so on. If you want to match a group of characters, you can enclose
them in parentheses. For example, regular expression "(ab)*" matches "",
"ab", "abab", "ababab", and so on. You'll learn more about it in the
following section on grouping.
Regular expression visualization
As we progress towards more complex examples, it might be helpful to visualize
regular expressions. In the future, Enso will provide a special visualization
for it, but for now, we recommend you to test your regular expressions using
either https://regex101.com or https://regex-vis.com. For example, a regular
expression "(ab)*(cd)*(ef)*" can be visualized as:
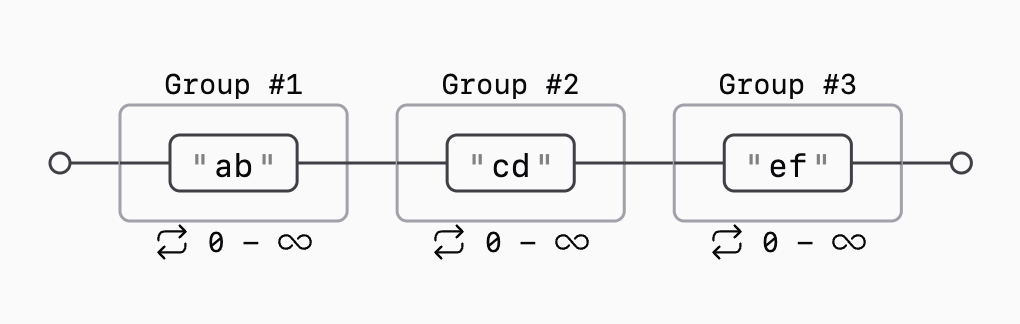
You should read it as "match either 'a' or 'b' zero or more times, then match 'c' or 'd' zero or more times, and finally match 'e' or 'f' zero or more times".
Alternatives
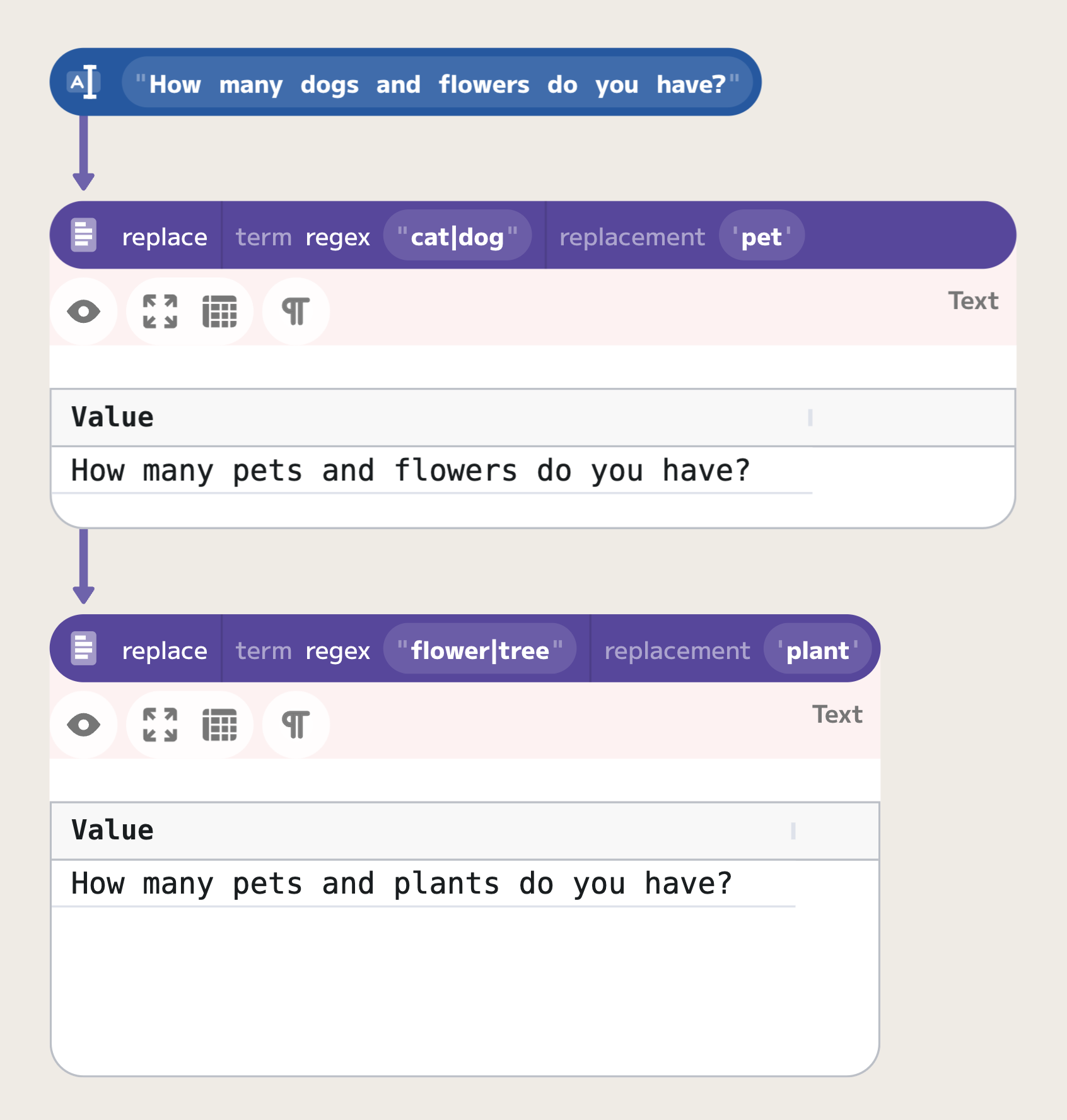
In order to match one of patterns, you can separate the patterns with |
character. For example, if you want to match either "cat" or "dog", you can
use the regular expression "cat|dog".
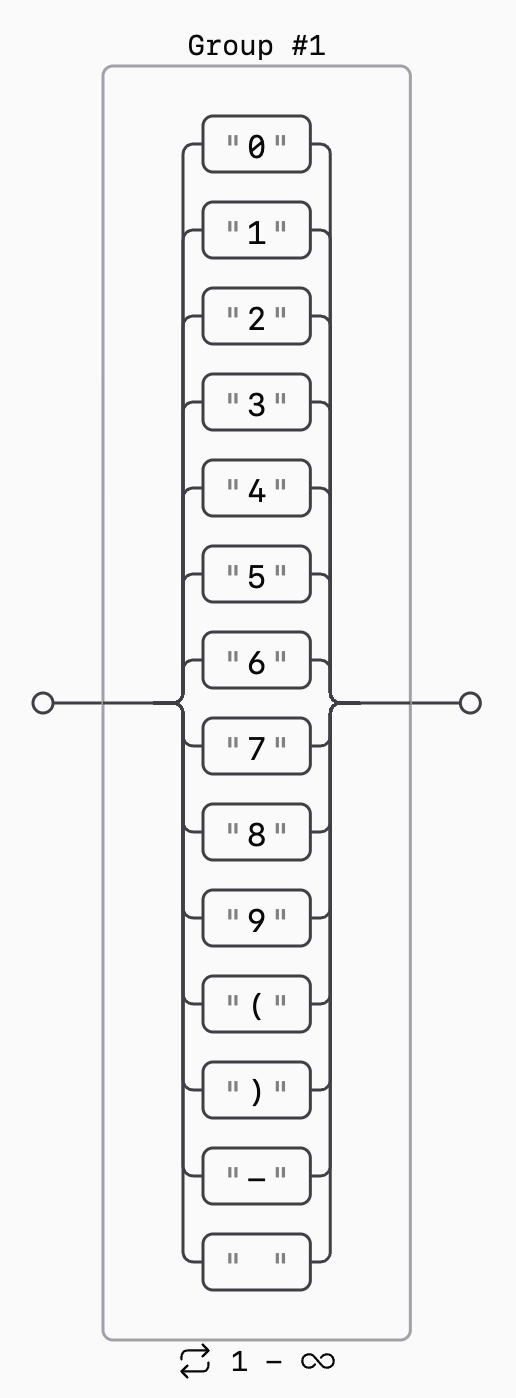
Let's see a more complex example now. Let's write a regular expression to match
phone numbers that can be written in one of the forms of 123-456-789,
(12) 345 678, or similar. We want to match any digit or space, or a dash, or a
parenthesis. As the parenthesis has a special meaning of grouping
sub-expressions, we need to escape them to match them literally. The first regular
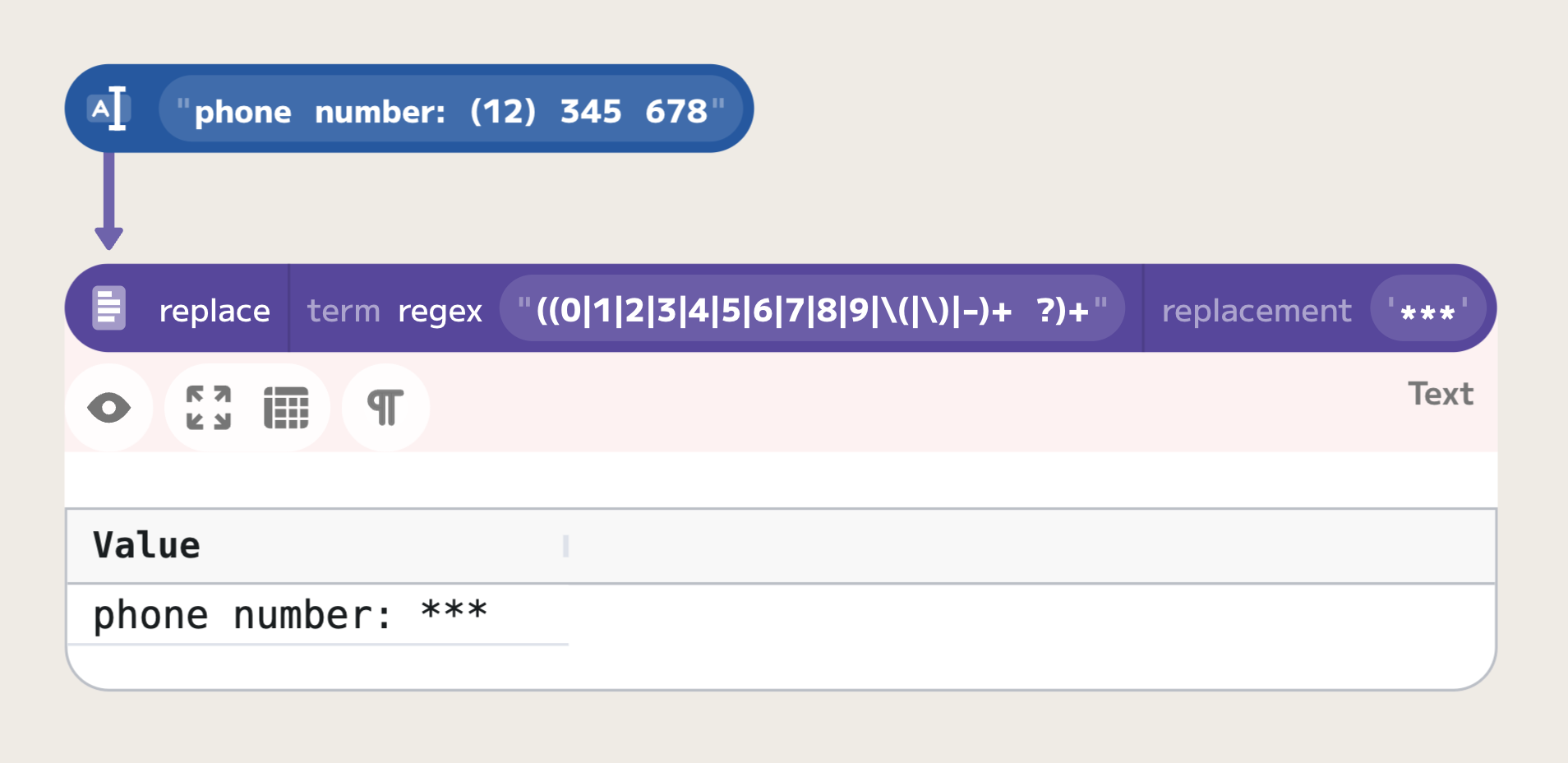
expression we can try is "(0|1|2|3|4|5|6|7|8|9|\(|\)|-| )+":
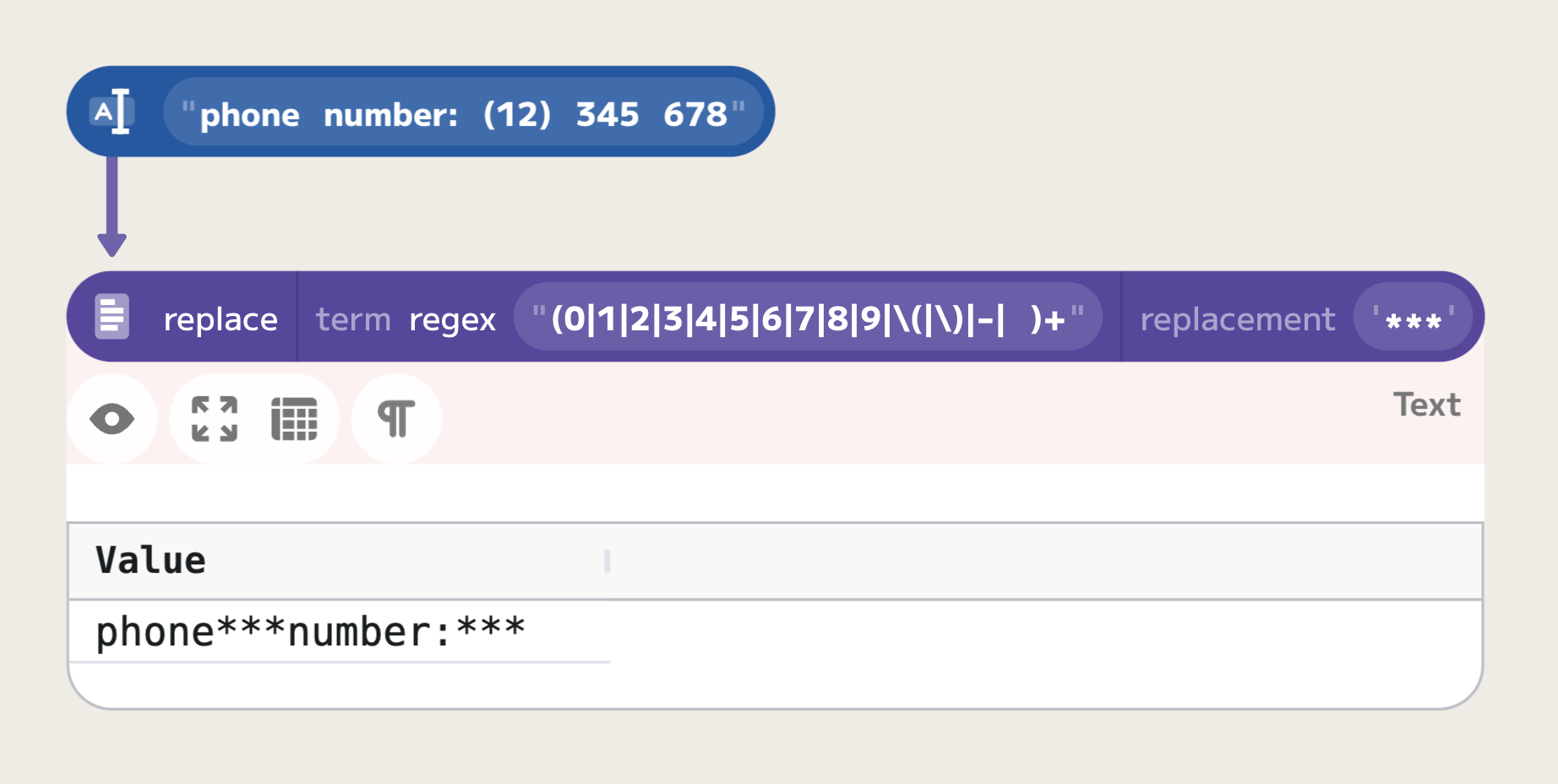
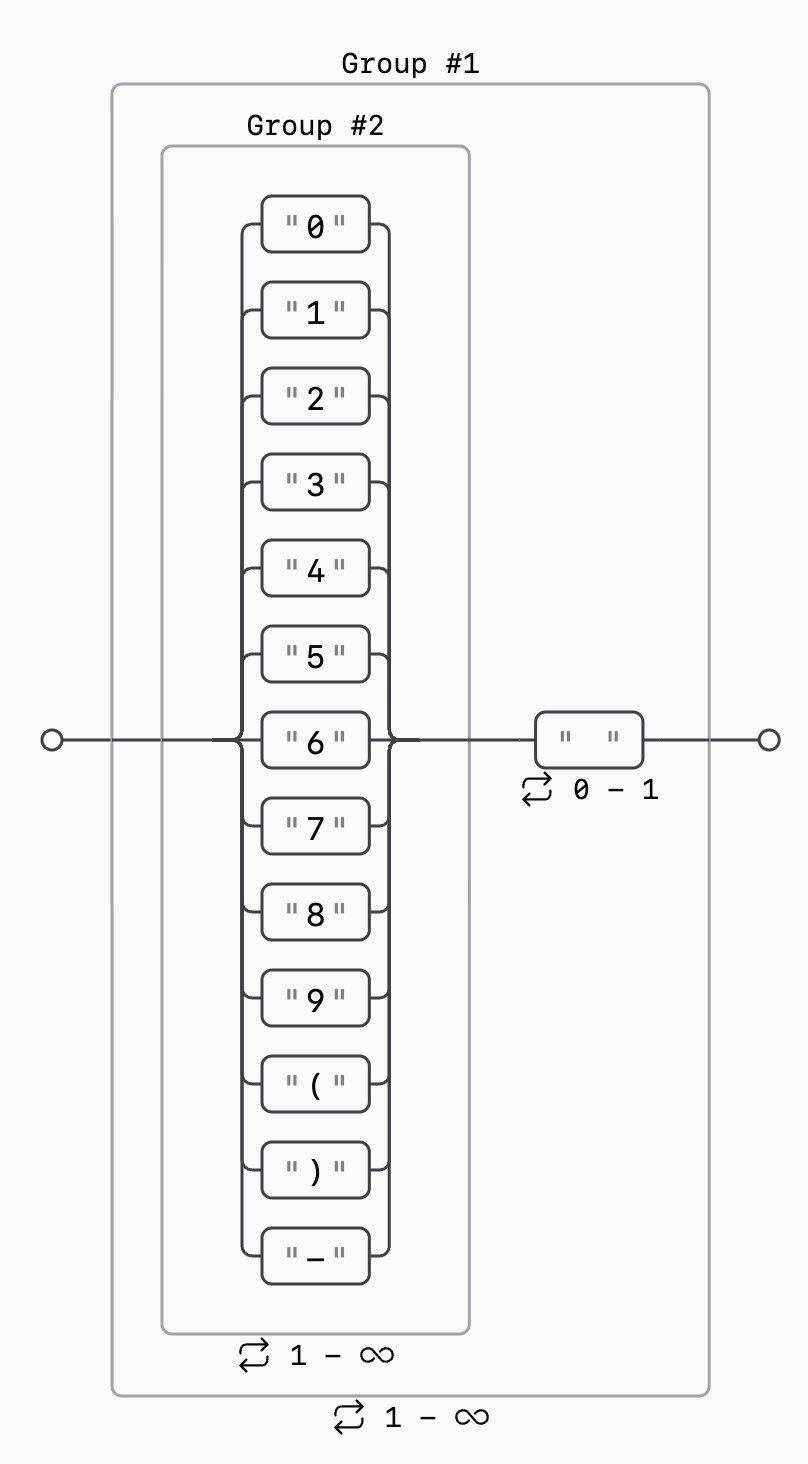
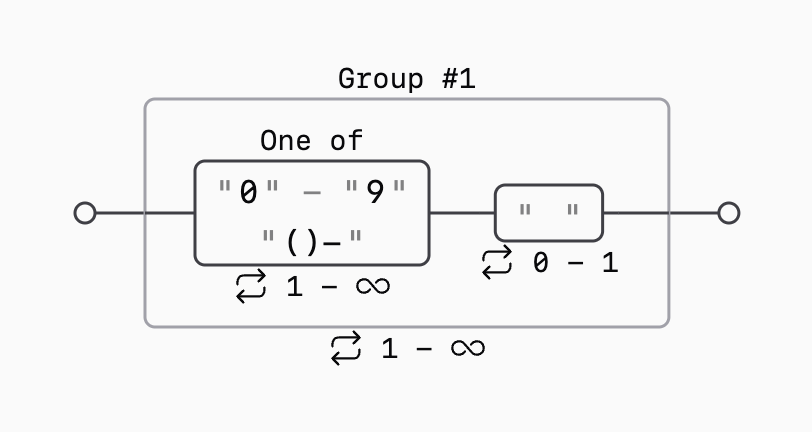
However, it does not work as intended. The regular expression matches spacing between words, as well as any other character. To fix this issue, we can first match on digits and parentheses, then optionally on a space, and then repeat the process. This can be achieved with the following regular expression: "((0|1|2|3|4|5|6|7|8|9|\(|\)|-)+ ?)+":
Character ranges
The syntax we used above is a little bit verbose and can very easily get complex. We can simplify it by using character ranges expressions. If we want to match a range of characters, using the above syntax can get quite verbose. Instead, you can use the character range syntax:
[abc]: Matches one of 'a', 'b', or 'c'.[a-z]: Matches any letter between 'a' and 'z'.
Please note, that you can mix the above syntax. For example, to match any lower
or upper-case letter between 'a' and 'z' or any number between 1 and 3, you can
use the regular expression "[a-zA-Z123]". In order to negate the range (match
everything but the range), you can use the ^ on the beginning. For example, to
match everything but digits, you can use [^0-9].
Let's use this syntax to accomplish the same task as in the previous example.
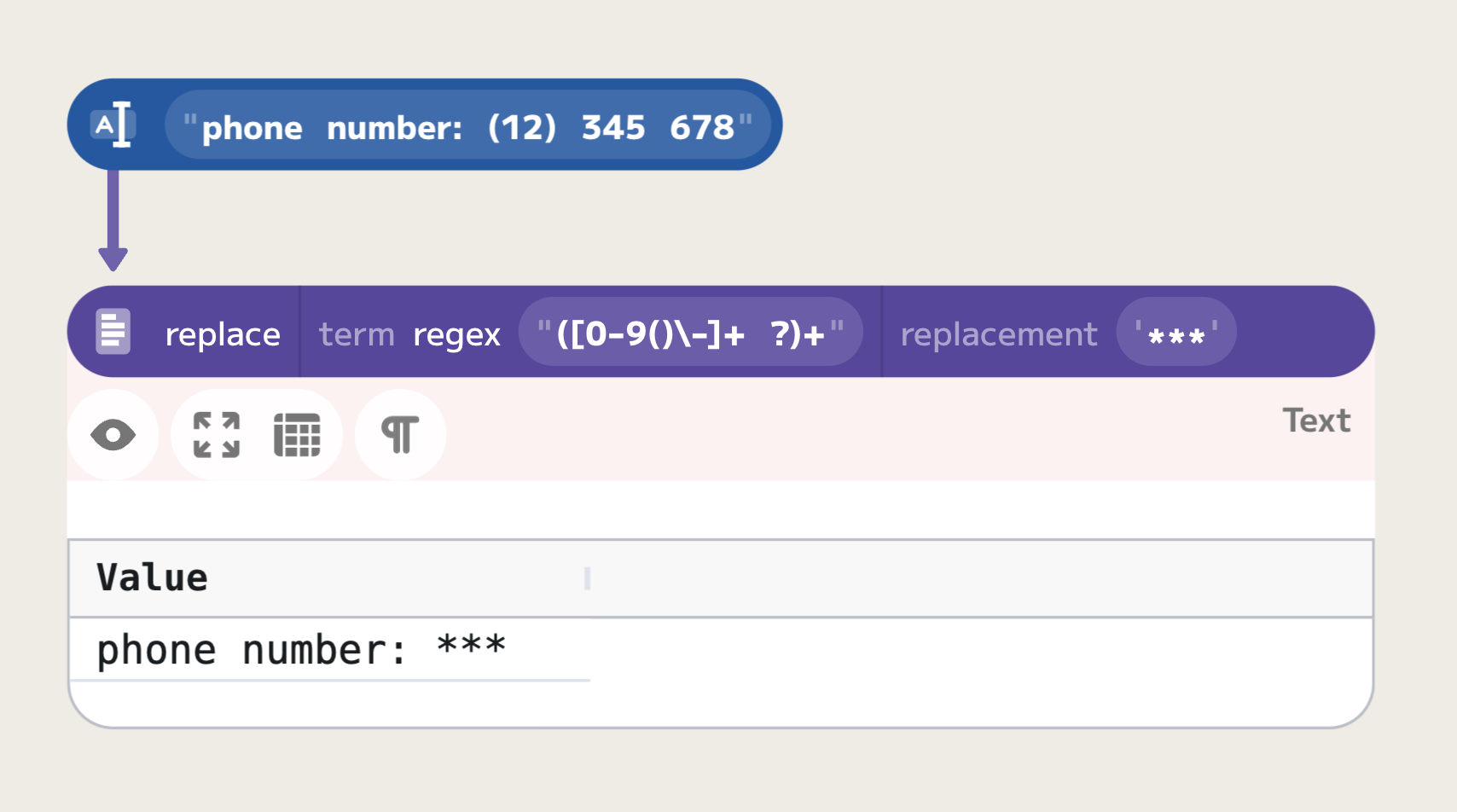
The regular expression that we used ("((0|1|2|3|4|5|6|7|8|9|\(|\)|-)+ ?)+") can
now be simplified to "([0-9()\-]+ ?)+". Please note that when using the character
range we do NOT need to escape the parentheses, as they do not have any special
meaning when used within the character range expression, but we need to escape
the dash, as it has a special meaning in the character range expression.
Character classes
In many cases, the character range syntax can get quite verbose. For example, it would
be very hard to use it to match any latin character. The syntax "[a-zA-Z]" matches any
lower or upper-case letter between 'a' and 'z' in the English alphabet (ASCII table), so
it will not match such characters as ł or ó. Character classes for the rescue! The
following symbols have special matching meaning:
\s: Any whitespace character, such as space, newline, tab, or any unicode whitespace character.\d: Any digit.\w: Any word character.\v: Any vertical whitespace.\h: Any horizontal whitespace.\R: Any unicode newline sequence.
In general, if you use the uppercase version of the symbol, it will inverse the match. For
example, \D matches anything but a digit. The only exception is \R that matches any unicode
newline sequence, and is not a negation of \r, which matches a "carriage return" symbol.
Unicode character classes
However, the above list is quite limited. There is one more special character class that allows
us to match based on unicode character classification, so called Unicode General Category properties.
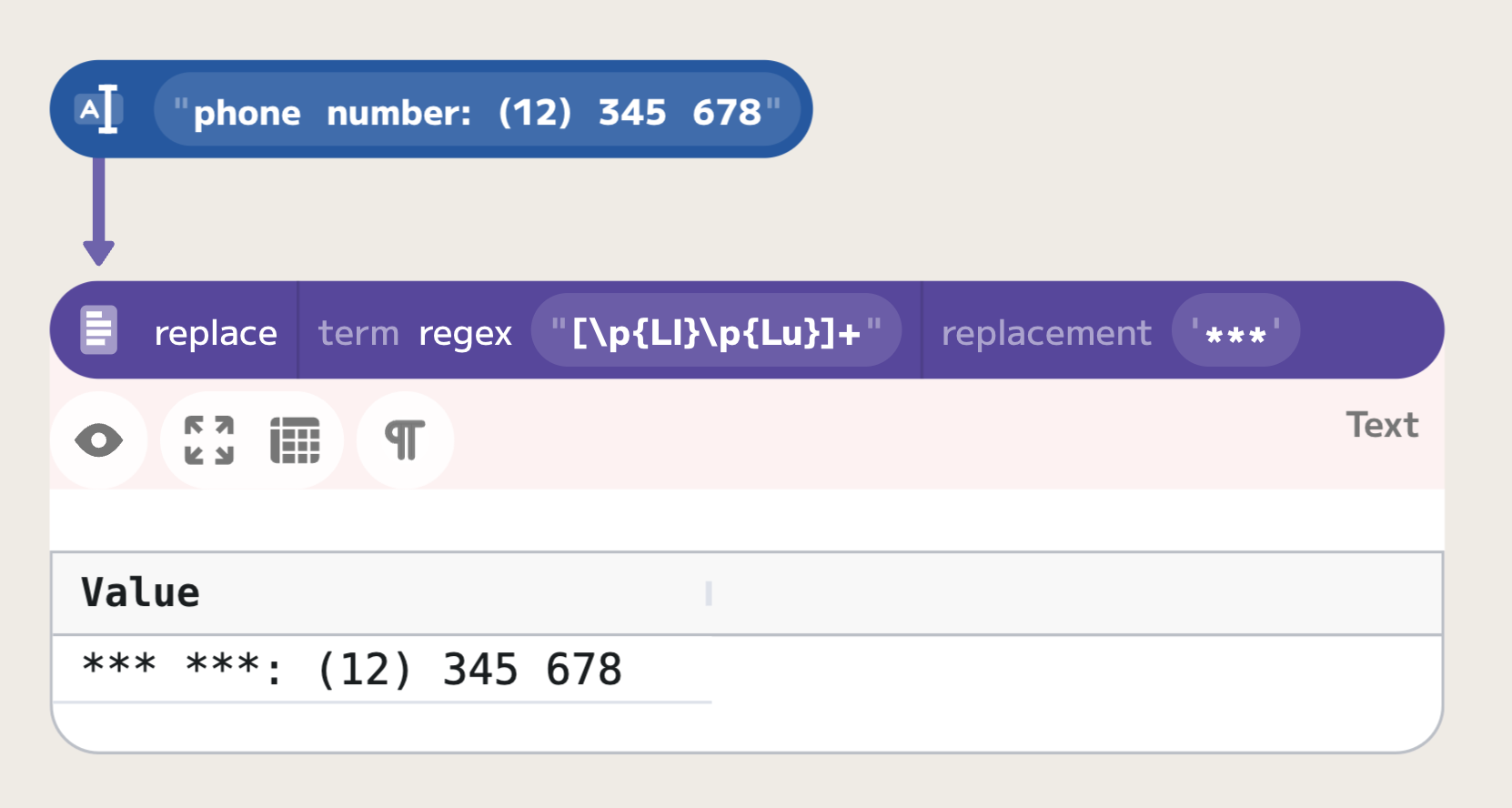
For example, the category of lowercase letters is called Ll, while the category of uppercase
letters is called Lu. For example, in order to match any lowercase or uppercase letter, including non-ASCII symbols,
we can use the following regular expression: "[\p{Ll}\p{Lu}]+".
Unnamed Groups
Groups in regular expressions are a fundamental feature that allow you to treat multiple pattern elements as a single unit. This capability is crucial for applying quantifiers to entire sequences and for extracting specific parts of strings for further processing. Groups are created by enclosing patterns within parentheses ( ).
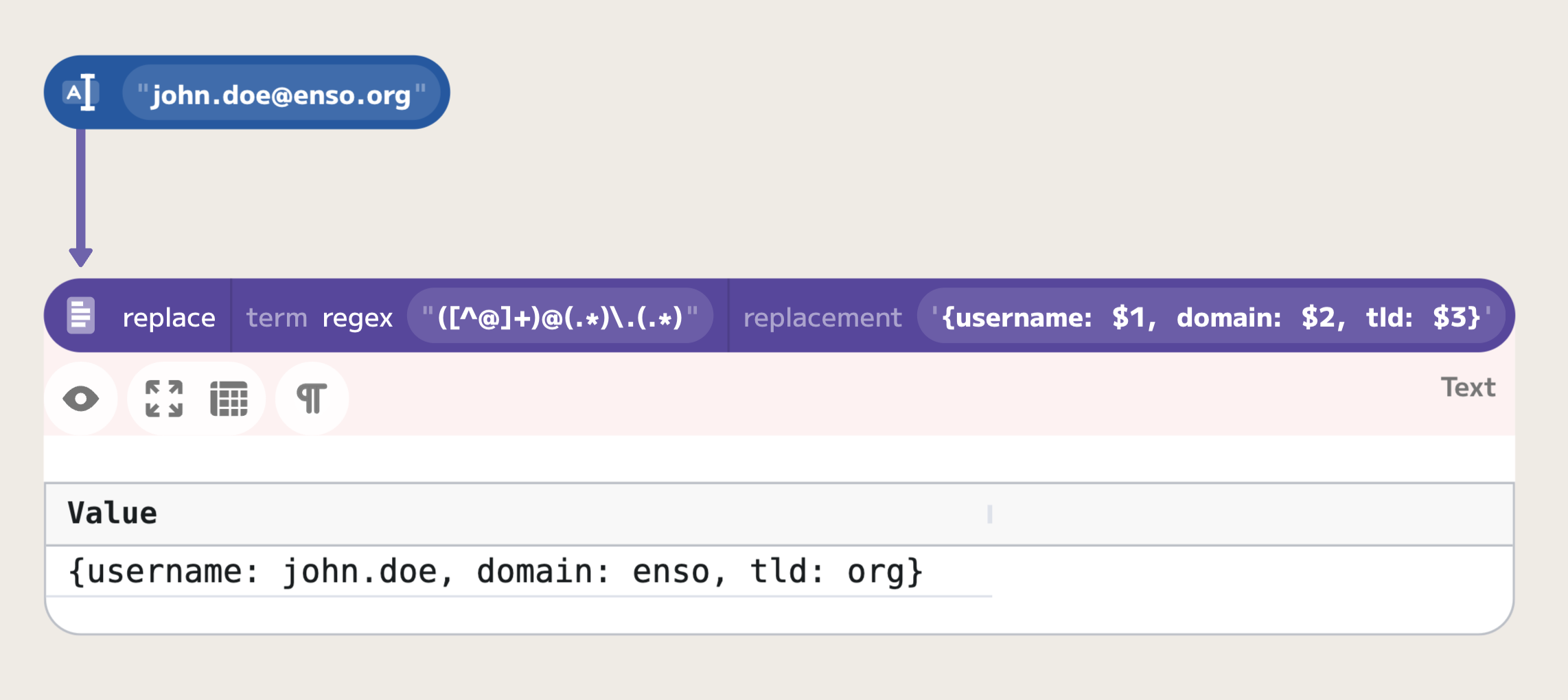
Consider the task of parsing an email address to separate its components using the regular expression ([^@]+)@(.*)\.(.*):
([^@]+): Captures one or more characters up to, but not including, the@symbol. This effectively isolates the username part of the email.(.*): After the@symbol, this group captures all characters. It stops before the last dot due to the subsequent dot match in the regex, ensuring the domain name is isolated correctly.(.*): This group captures everything after the last dot, typically the top-level domain (TLD).
These groups can be referenced using $1, $2, etc., where the number corresponds to the position of the group in the regex. For instance, if you want to reformat the email address into a JSON string, you might use a replacement pattern like {username: $1, domain: $2, tld: $3}:
Named Groups
Named groups extend the functionality of unnamed groups by allowing you to assign descriptive names to each group, enhancing readability and maintainability, especially in complex regular expressions. Named groups are defined using the syntax (?<name>pattern).
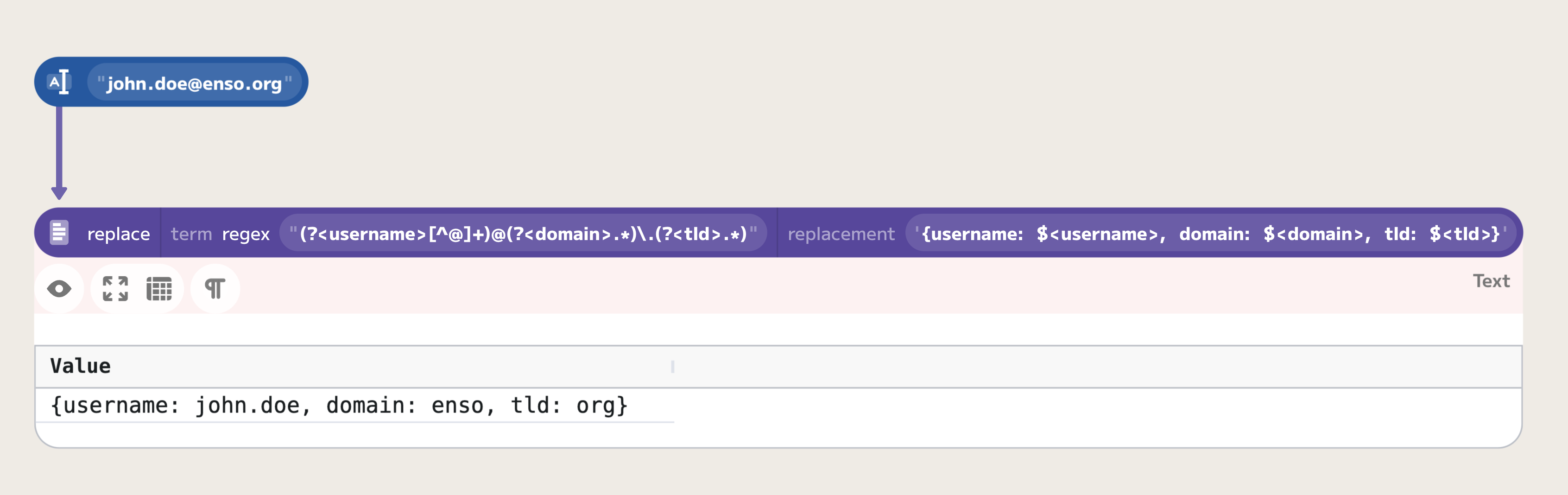
Applying this to our email example, you could use the expression (?<username>[^@]+)@(?<domain>.*)\.(?<tld>.*):
(?<username>[^@]+): Captures the username portion of the email.(?<domain>.*): Captures the domain portion of the email, stopping before the last dot due to the placement of the dot match in the regex.(?<tld>.*): Captures the top-level domain.
Named groups are referenced in replacements using ${name}, making it clear which part of the original text is being manipulated. For example, to format the email address as a JSON string, you might use a pattern like {username: $<username>, domain: $<domain>, tld: $<tld>} in your replacement string.
This use of named groups can significantly simplify the management of data transformations in Enso, especially when dealing with complex or multiple data sources:
Lookarounds
Lookarounds in regular expressions are a powerful feature that allow you to assert certain conditions for a match without including the asserted text in the actual match. Lookarounds are particularly useful for matching patterns based on the presence or absence of certain prefixes or suffixes in the text, without capturing those elements themselves. There are four types of lookarounds:
- Positive Lookahead
(?=...): Checks for the existence of a specified pattern after the current position in the text, without consuming any of the string. For example,\d(?=px)matches a digit only if it is followed by 'px'. - Negative Lookahead
(?!...): Ensures that a specified pattern does not follow the current position in the text. For instance,\d(?!px)matches a digit only if it is not followed by 'px'. - Positive Lookbehind
(?<=...): Checks for the existence of a specified pattern before the current position. For example,(?<=\$)\d+matches one or more digits only if they are preceded by a dollar sign. - Negative Lookbehind
(?<!...): Ensures that a specified pattern does not precede the current position. For instance,(?<!\$)\d+matches one or more digits only if they are not preceded by a dollar sign.
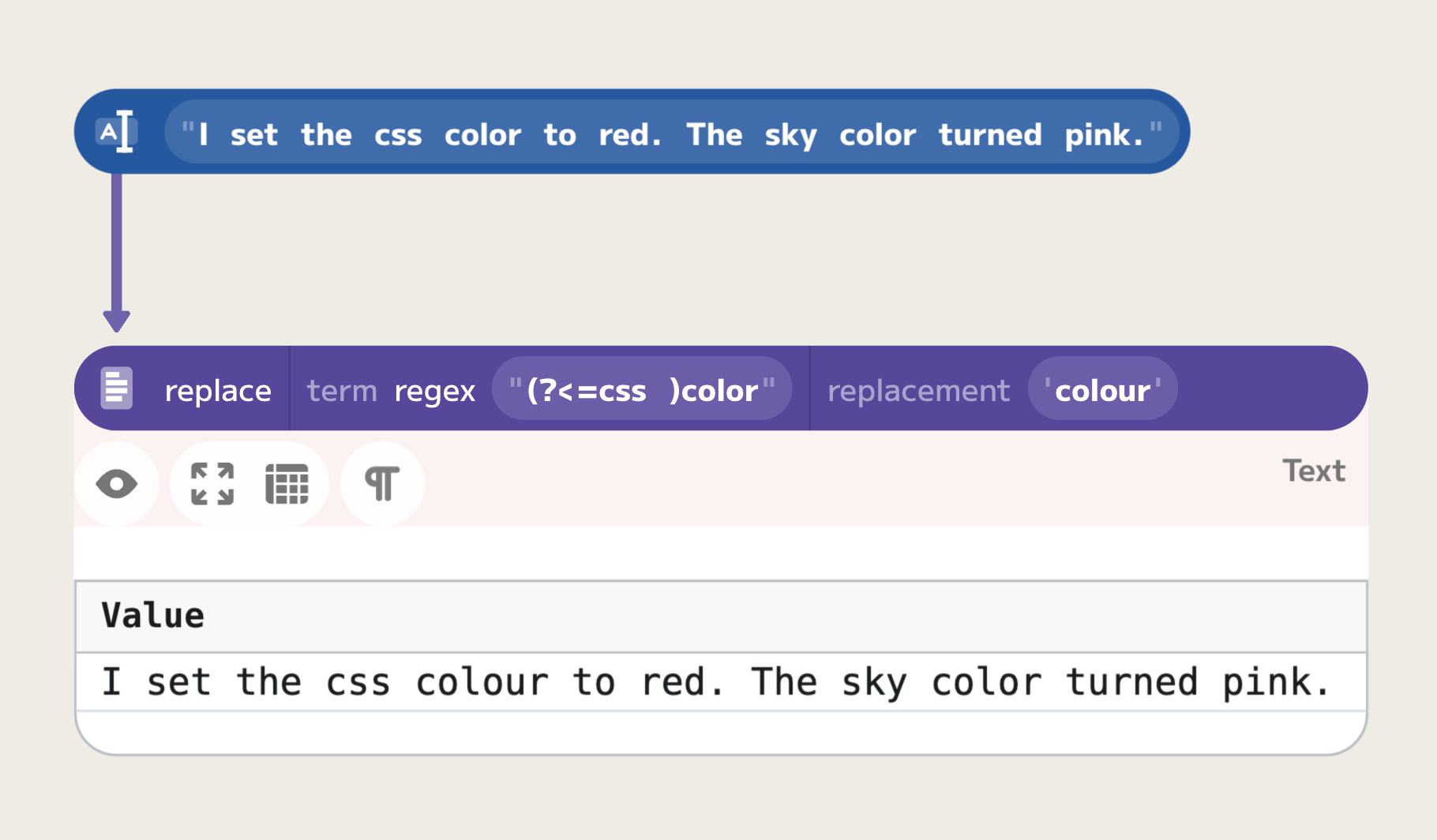
Lookarounds are often used in situations where you need to modify text surrounding a pattern without changing the pattern itself. For example, if you want to replace the word 'color' with 'colour' only when it appears after 'css', you can use a lookbehind in your replacement operation like (?<=css )color and replace it with 'colour'.
In Enso, utilizing lookarounds can enhance the specificity of your data transformations, allowing for precise manipulations based on the context of the data:
Lookarounds do not consume characters in the string, but merely assert whether a match is possible, making them an essential tool for complex text processing tasks in Enso. They enable you to perform checks and manipulations based on the context of the text without altering the parts of the string you are checking against.
Greedy vs. Lazy Quantifiers in HTML Tag Parsing
Understanding the difference between greedy and lazy quantifiers in regular expressions is crucial, especially when parsing or extracting data from HTML content. Greedy quantifiers attempt to match as much text as possible, while lazy quantifiers match as little as possible, stopping at the first valid endpoint they encounter.
Greedy Quantifiers
Greedy quantifiers expand the match as far as possible through the string until the pattern fails. When dealing with HTML tags, this behavior can lead to unintended matches that encompass more than the desired tag. Let's consider the following input HTML snippet: <div>Hello <span>world</span></div>. If we use a greedy quantifier pattern like <.+>, it will match the entire string from <div> to </div>, including the nested <span> tag.
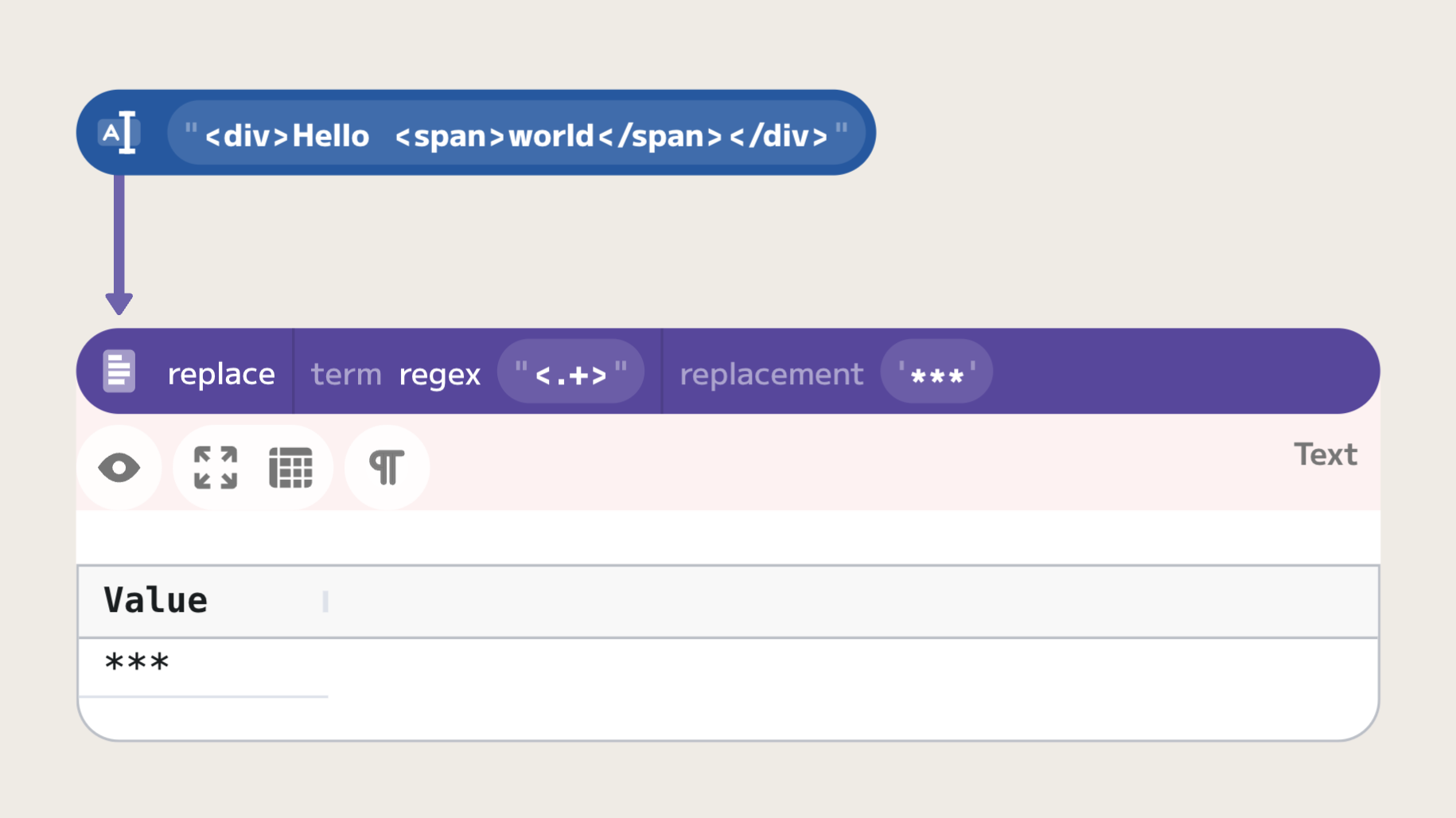
This example shows that the greedy regex does not stop after matching the first closing >, but instead continues until it reaches the last > in the string. This behavior is often not desired when the goal is to match individual HTML tags.
Lazy Quantifiers
Lazy quantifiers, on the other hand, take the minimum necessary characters to fulfill the pattern, making them ideal for tasks like HTML tag parsing where the end of the pattern is typically close to its start. Let's consider the previous example, this time using lazy quantifiers: <.+?>. When applied to the same HTML snippet, the lazy quantifier correctly matches <div> and <span> separately.
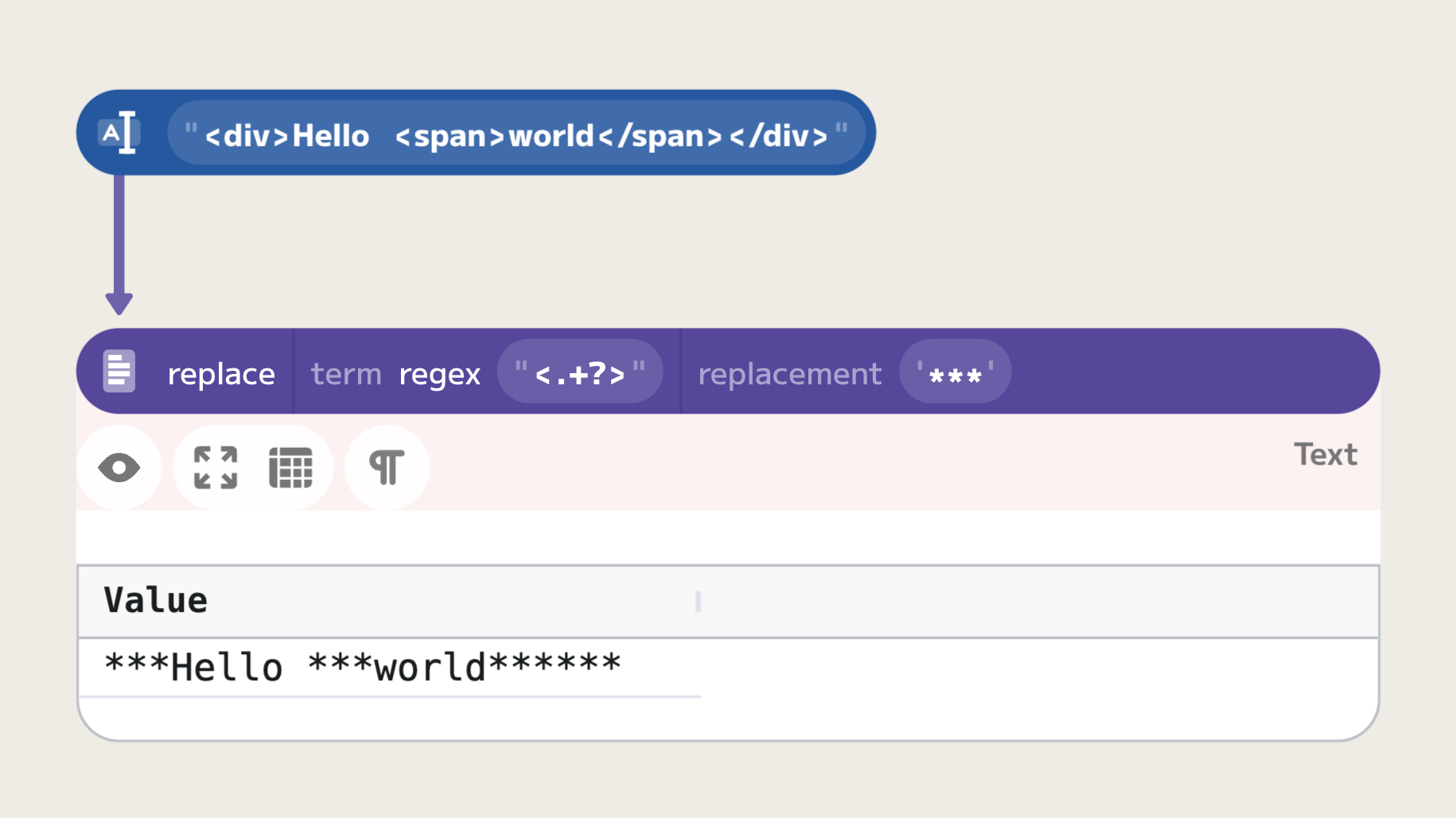
The lazy pattern <.+?> tells the regex engine to match as few characters as possible while still conforming to the .+ pattern. This stops the match at the first > encountered, which accurately captures each HTML tag individually.
In the context of nested structure parsing, like HTML tag parsing, lazy quantifiers are generally more effective than their greedy counterparts due to their precision in stopping at the nearest pattern endpoint. Understanding when to use greedy vs. lazy quantifiers is key in many regular expression tasks, but particularly so in parsing structured data like HTML where precise extraction of elements is often required. By using lazy quantifiers, you can avoid common pitfalls associated with the overreaching nature of greedy regex patterns.