Regular Expressions
Enso's regular expression support is based on the EMCAScript standard with a few options preset. The following options are always enabled in Enso:
u(Unicode) : Treats the pattern as a sequence of Unicode code points.g(Global) : Matches all occurrences of the pattern in the input string.s(Single Line) : The dot (.) matches all characters, including line terminators.
If specified, the i (Case Insensitive) option is also enabled. Other options are not supported within Enso.
Functions Supporting Regular Expressions
While not an exhaustive list, the following functions support regular expressions within Enso:
- Text.find : Finds the first occurrence of a pattern in a text value.
- Text.find_all : Finds all occurrences of a pattern in a text value.
- Text.match : Matches a pattern against the whole text value.
- Text.replace : Replaces all occurrences of a pattern in a text value.
- Column.text_replace : Replaces all occurrences of a pattern in a column.
Note: when using regular expressions within a database context, the expression is evaluated by the database engine. This means that the regular expression syntax may vary depending on the engine being used.
Regular expressions can also be used when specifying columns in various table based functions. For example, Table.select_columns can take a regular expression as a column selector. As this is evaluated by the Enso engine, the regular expression syntax is consistent with the rest of the language including when a database engine is used.

Regular Expression Syntax
Regular expression in Enso are written using the regex function followed by a Text value of the pattern. For example, regex "a+" will match one or more a characters.
The following quick reference provides a brief overview of the syntax used in regular expressions. For a more reference and tool to help create Regex, Enso recommend RegExr.
Character Classes
.: Matches any single character including line terminators.x|y: Matches eitherxory.[xyz]: Matches any of the charactersx,y, orz.[a-z]: Matches any character in the rangeatoz.[a-zA-Z0-9]: Matches any character in the rangeatoz,AtoZ,0to9.[^xyz]: Matches any character not in the setx,y, orz.[^a-z]: Matches any character not in the rangeatoz.^: Matches the start of the input string.$: Matches the end of the input string.\b: Matches a word boundary.\B: Matches a non-word boundary.
Character Sets
\d: Matches any digit character (0-9).\D: Matches any non-digit character.\w: Matches any word character (0-9, a-z, A-Z, _).\W: Matches any non-word character.\s: Matches any whitespace character.\S: Matches any non-whitespace character.
Special Characters
\: Escapes a special character.\n: Matches a line feed character.\r: Matches a carriage return character.\t: Matches a tab character.\xhh: Matches the character with the hex codehh.\uhhhh: Matches the character with the Unicode code pointhhhh.
Quantifiers
*: Matches the preceding element zero or more times (greedily).*?: Matches the preceding element zero or more times (non-greedy).+: Matches the preceding element one or more times.?: Matches the preceding element zero or one time.{n}: Matches exactlynoccurrences of the preceding element.{n,}: Matchesnor more occurrences of the preceding element.{n,m}: Matches at leastnand at mostmoccurrences of the preceding element.
Groups
(...): Captures the matched subexpression.(?<name>...): Captures the matched subexpression into a named group.(?:...): Groups an expression without capturing it.\n: Matches the result of thenth captured group.\k<name>: Matches the result of the named captured group.$n: Matches the result of thenth captured group when used in a replacement string.$<name>: Matches the result of the named captured group when used in a replacement string.
Note: Marked groups are numbered from 1 upwards, from left to right. Group 0 refers to the whole matched value.
Named_Patterns
Enso has some predefined named patterns that can be used within regular expressions. These patterns are:
Named_Pattern.Leading_Whitespace: Matches one or more whitespace characters at the beginning of a string (^\s+).Named_Pattern.Trailing_Whitespace: Matches one or more whitespace characters at the end of a string (\s+$).Named_Pattern.Duplicate_Whitespace: Matches one or more whitespace characters that are preceded by another whitespace character (?<=\s)\s+).Named_Pattern.All_Whitespace: Matches one or more whitespace characters anywhere in a string(\s+).Named_Pattern.Newlines: Matches one or more newline characters ((?:\r\n?|\n)).Named_Pattern.Leading_Numbers: Matches one or more digits at the beginning of a string (^\d+).Named_Pattern.Trailing_Numbers: Matches one or more digits at the end of a string (\d+$).Named_Pattern.Non_ASCII: Matches any character that is not in the ASCII range (0x00-0x7F) ([^\x00-\x7F]).Named_Pattern.Tabs: Matches any tab characters (\t).Named_Pattern.Letters: Matches any single alphabetic character (both lowercase and uppercase)([a-zA-Z]).Named_Pattern.Numbers: Matches any digits (\d).Named_Pattern.Punctuation: Matches any punctuation characters from the set:,,.,!,?,(,),:,;,',"([,.!?():;\'\"]).Named_Pattern.Symbols: Matches any characters that are not an alphabetic character, digit, or whitespace ([^a-zA-Z\d\s]).
These can be used where regular expressions are expected. For example, "Hello World!".replace Named_Pattern.Letters "" will return " !".
Using regex to create Tables or Columns
The parse_to_table function on Text values allows for the creation of a table using regular expressions. Each match of the pattern within the text is created as a new row.
Likewise the parse_to_columns function on a Table can be used to parse a column of text values into a set of columns based on a pattern. Each row is processed one row at a time, with each match of the pattern within the cell's text is created as a new row. Other rows are repeated.
The marked groups are used to define the columns. If there are no marked groups, the whole match is used with a name of Column. If there are marked groups then if the group has a name this is used as the column name, otherwise the group number is used with Column as a prefix (e.g. Column 1).
For example, '1,2,3\n4,5,6\n7,8,9' can be parsed into a table with 3 columns using the pattern (?<First>\d+),(\d+),(?<Last>\d+). This will create a table with 3 columns, each containing the values from the corresponding group in the pattern.
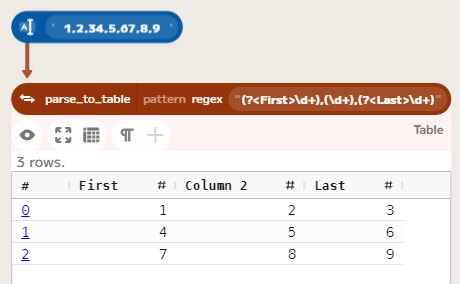
Example Regular Expressions
Extract text from a column and replace the value of that column with just the extracted text
- Find a string that is in the pattern aaa-####### (where 'a' is any upper or lower case character), putting it into a named group, and then replace what was in the InputString column with just aaa-#######.
table1 = Table.new [['InputString', ['PRO-1234567 xyz testing site ', 'PRO-1234567 xyz testing site', 'xyz testing site pro-1234567', 'xyz testing PRO-1234567 site', 'PRO-1234567_xyz testing site']]]
column1 = table1.text_replace ['InputString'] (regex ".*([a-zA-Z]{3}-\d{7}).*") "$1"
- Find a string that is enclosed in parentheses "(" ")" and return the word inside.
table2 = Table.new [['InputString', ['Aves (Birds) ', 'Reptilla (Reptiles)', 'Lots of text and Aves (Birds) and then lots more text']]]
column2 = table2.text_replace ['InputString'] (regex ".*\((.*)\).*") "$1"
Extract text from string and put it into new columns
- Find phone numbers and Social Security Numbers in a text column and extract them to new columns named [PhoneNumber] and [SSN].
table3 = Table.new [['Name', ['Sarah Brown', 'David Williams', 'Laura Martinez']], ['Notes', ['called customer service with phone number (497)-102-2376 and social security number 949-10-9142', 'followed up with phone number (421)-773-3064 and social security number 339-88-8665', 'requested a callback with phone number (991)-681-9164 and social security number 316-11-3792']]]
table4 = table3.parse_to_columns 'Notes' '(?<PhoneNumber>\\(\\d{3}\\)-\\d{3}-\\d{4}).*?(?<SSN>\\d{3}-\\d{2}-\\d{4})'
- Extract Match Type, Duration in Minutes and Duration in Seconds and put them in new columns
table101 = Table.new [['A', ['Match recap, duration 2 minutes and 43 seconds► 2:43', 'Match recap, duration 3 minutes and 10 seconds► 3:10', 'Match recap, duration 2 minutes and 34 seconds► 2:34', 'Match recap, duration 2 minutes and 58 seconds► 2:58']]]
table102 = table101.parse_to_columns 'A' 'Match (?<Type>recap|highlights), duration (?<minutes>\\d+) minutes? and (?<seconds>\\d+) seconds?.*'