Enso's Expression Syntax
Enso's expression syntax is a simple, yet powerful, way to manipulate data in Enso. It is designed to be familiar to those used to writing SQL formulas or Excel table based functions.
This guide gives an overview of the syntax and a summary of the functions currently available.
To enter an expression, choose the <Expression> entry from the dropdown. They can be used in many places where a column is used, such as in a filter or aggregate components.
Currently, it is not possible to use Enso literals inside the expression syntax but this is planned for a later release.
How to use this guide
In the documentation below, you will see Enso functions with examples. This text plugs into Enso components that accept expressions including the set, filter and aggregate.
An example may show:
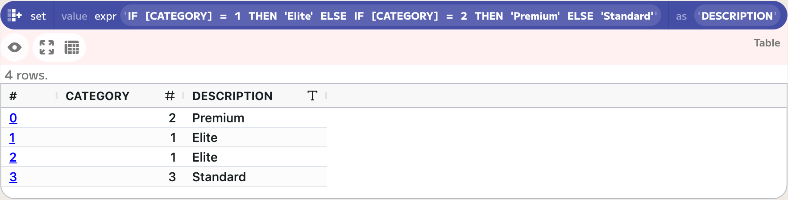
IF [CATEGORY] = 1 THEN 'Elite' ELSE IF [CATEGORY] = 2 THEN 'Premium' ELSE 'Standard'
Below is how this function would appear in a set component:
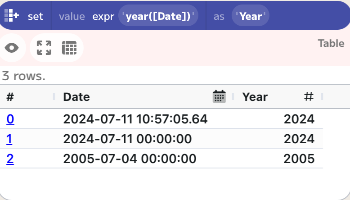
For simple examples below, such as year(2024-07-04) returns 2024, the date shown implies a value from a row in a DATE column.
Below is how this function would appear in a set component:
Functions can also be combined together to create much more complex expressions. For example:
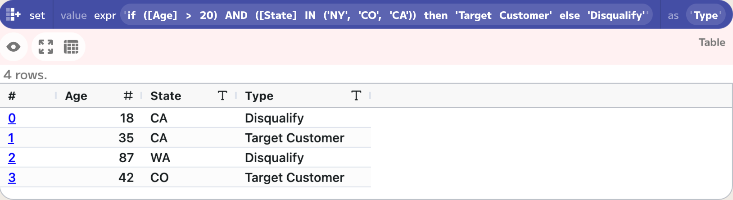
if ([Age] > 20) AND ([State] IN ('NY', 'CO', 'CA')) then 'Target Customer' else 'Disqualify'
Below is how this expression would appear in a set component:
Syntax description
The Expression syntax is similar to that of SQL Server syntax. The key features of the syntax are:
- Unlike in Enso code, whitespace is ignored.
- Expressions are case-insensitive for all identifiers, except for column names.
- Functions are invoked with argument lists in parentheses.
- The function name is case-insensitive.
- The first argument of the function is the column to operate on.
- Some functions allow for a variable number of arguments, for example
coalesceandis_in. - No support for comments within the expression (at least for version 1).
Literals
The following literals are supported:
- Nothing:
nullornothing(not case sensitive). This equates to a column of Nothing values of type Nothing. - Boolean:
true,false(not case sensitive). - Number: Support for
_separators in numbers. No support for hex, octal or binary literals. - Text: Two formats supported:
- If in double-quotes, then Excel style with only
""as an escape sequence for". For example:"This is a ""quoted"" string with 'another'.". - If in single quotes, then Python style with usual supported escapes. For example:
'This is a "quoted" string with \'another\'.'.
- If in double-quotes, then Excel style with only
- Date: Should be written in ISO format, e.g.
2020-01-01surrounded by#characters. For example,#2020-01-01#. - Time: Should be written in ISO format, e.g.
14:00:00surrounded by#characters. For example,#14:00:00#.- Seconds are optional, so
#12:00#is also valid.
- Seconds are optional, so
- Parts of seconds are optional allowing more precise specification, so
#12:00:00.123#is also valid. - DateTime: Enso uses ISO format yyyy-mm-dd HH:MM:SS to represent dates and times. To use a date constant in a function, it needs to be specified as an ISO formatted date, surrounded by
#characters. For example, 15, April 2020 at 2PM would be represented as#2020-15-04T14:00:00#.- As with Time, seconds and part of seconds are optional.
- Time zone offset is also optional allowing users to specify a shift from UTC.
Additionally, the name of the TimeZone can be specified in[]brackets either after the offset or on its own.
If no time zone or offset is passed the local system time zone will be used. Enso uses the ISO format yyyy-mm-dd HH:MM:SS to represent dates and times. If a DateTime value is not in this format, Enso reads it as a char. To convert a column to enable the use of the DateTime functions, use theparsecomponent to do so.
- Regex: Regular Expression literals are written surrounded by
r/and/characters. For exampler/.*/.- If you want to write a forwardslash in your regular expression it needs to be escaped with a backslash. For example
r/\//matches a single forwardslash. - Other regular expression escape characters work as normal with a backslash escape sequence.
- Alternatively you can create a Regular Expression using the regex function. For example
regex(".*"). - You can find more information about Enso regular expressions here
- If you want to write a forwardslash in your regular expression it needs to be escaped with a backslash. For example
Column Names
Columns are represented by their name in square brackets, e.g. [First Name]
- Any closing brackets in the name need to be escaped (by being doubled) if it is part of the column name.
e.g.[First]] Name]refers to a column namedFirst] Name. - Column names will be case-sensitive (unless the backing table allows case-insensitive column names).
- The column name must be in square brackets.
- The escaping of
]is based on the Alteryx syntax.
Note: this is different to SQLite, MySQL and Postgres, which use " to identify columns. However, this is consistent with SQL Server, Excel, Tableau and Alteryx syntaxes.
Operators
The following operators are supported:
- Arithmetic:
+,-,*,/,%(modulo),^(power),-(unary minus). - Comparison:
=,!=(and<>),>,>=,<,<=.- Note:
=and==are equivalent as there is no assignment operation in the expression syntax.
- Note:
- Logical:
and,or,not(and!). - String:
+(concatenation). - Date:
+(addition of period),-(subtraction of period),-(subtraction of another date to a duration). - Time:
+(addition of a duration),-(subtraction of a duration),-(subtraction of a time). - DateTime:
+(addition of duration or period),-(subtraction of duration or period),-(subtraction of another date to a duration).
Additional special operators:
IS NULLfor checking if a value is null.IS EMPTYfor checking if a value is null or"".LIKEfor comparing against SQL patterns.IN (...)for checking if a value is in a list of values.<input> BETWEEN <lower> AND <upper>for checking if a value is between two values
Precedence
The following specifies the operator precedence. Operators at the same level have the same precedence and are evaluated left to right.
-(unary minus)^(power)*,/,%+,-=,!=(or<>),>,>=,<,<=IS NULL,IS NOT NULL,IS EMPTY,IS NOT EMPTY,LIKE,NOT LIKE,IN (...),NOT IN (...),BETWEEN <lower> AND <upper>NOT(or!)ANDOR
The precedence ensures that expressions are evaluated in the expected order (following the PEDMAS rules). For example, a + b * c would be evaluated as a + (b * c).
Please note, that whitespace does not affect the precedence of operators.
Conditional Functions
A conditional function performs an action or calculation based on a test of data using an IF statement. Use a conditional function to provide a TRUE or FALSE result to highlight or filter out data based on specific criteria. Conditional functions can be used with any data type.
IF condition THEN true ELSE false ENDIF
-
IF <condition> THEN <true> ELSE <false>. Returns<true>if the<condition>is true, else returns<false>. -
There must be an
ELSEclause, this is not optional. -
You may optionally include an
ENDIF(orEND) at the end of the statement.Example:
IF [CATEGORY] = 1 THEN 'Elite' ELSE 'Standard'CATEGORY Result 2 Standard 1 Elite 1 Elite 3 Standard
IF condition1 THEN true1 ELSE IF condition2 THEN true2 ELSE false ENDIF
IF <condition1> THEN <true1> ELSE IF <condition2> THEN <true2> ELSE <false> ENDIF.: Returns <true1> if the first condition <condition1> is true, else returns <true2> if the second condition <condition2> is true, else returns <false>.
-
Multiple ELSE IF statements can be included.
-
There must be an
ELSEclause, this is not optional. -
You may optionally include an
ENDIF(orEND) at the end of the statement.Example:
IF [CATEGORY] = 1 THEN 'Elite' ELSE IF [CATEGORY] = 2 THEN 'Premium' ELSE 'Standard'CATEGORY Result 2 Premium 1 Elite 1 Elite 3 Standard
IIF
IIF (<boolean>,<true>,<false>): Returns <true> if <boolean> is true, else returns <false>.
-
If always evaluates both
<true>and<false>, even though it returns only one of them. Because of this, you should watch for undesirable side effects. For example, if evaluating<false>results in a division by zero error, an error occurs even if<boolean>is True.Example:
IIF ([CATEGORY] = 1,'Elite', 'Standard')CATEGORY Result 2 Standard 1 Elite 1 Elite 3 Standard
SWITCH
There is currently no support for SWITCH statements inside the expression syntax.
Functions
DateTime
DateTime functions allow you to perform an action or calculation on a date and time value. Use DateTime functions to extract a part of a DateTime value.
Enso uses the ISO format yyyy-mm-dd HH:MM:SS to represent dates and times. If a DateTime value is not in this format, Enso reads it as a char. To convert a column to enable the use of the DateTime functions, use the parse component to do so.
-
today(): Returns the current date. -
tomorrow(): Returns the date for yesterday (midnight in the local timezone). -
yesterday(): Returns the date for yesterday (midnight in the local timezone). -
now(): Returns the current date and time. -
time(): Returns the current time. -
year(<column>): Returns the numeric value for the year in a date-time value.- Example:
year(2024-07-04)returns2024
- Example:
-
month(<column>): Returns the numeric month of the year.- Example:
month(2024-07-04)returns7
- Example:
-
day(<column>): Returns the numeric day of the month.- Example:
day(2024-07-04)returns4
- Example:
-
day_of_week(<column>): Returns the numeric day of the week (1 Mon - 7 Sun).- Example:
day_of_week(2024-07-04)returns4
- Example:
-
day_of_year(<column>): Returns the numeric day of the year.- Example:
day_of_year(2024-07-04)returns186
- Example:
-
date_part(<column>,<part>): Returns the part of the date specified.<part>options:..year,..quarter,..month,..week,..day- Example:
date_part(2024-12-04,..Year)returns2024
- Example:
-
date_add(<column>,<value>,<period>)Returns a new date offset by the value and period specified.<period>options:..year,..quarter,..month,..week,..day- Example:
date_add(2000-01-01,20,..Month)returns2021-09-01
- Example:
-
date_diff(<date1>,<date2>,<period>): Returns the number of periods between two dates.<period>options:..year,..quarter,..month,..week,..day- Example:
date_diff(2024-01-01,2024-12-04,..day)returns338
- Example:
-
hour(<column>): Returns the numeric hour of the day.- Example:
hour(2024-07-04 12:50.29.25)returns12
- Example:
-
minute(<column>): Returns the numeric minute of the hour.- Example:
minute(2024-07-04 12:50.29.25)returns50
- Example:
-
second(<column>): Returns the numeric second of the minute.- Example:
second(2024-07-04 12:50.29.25)returns29
- Example:
-
truncate(<column>): Truncate the decimal part of a number or the time part of a date time.- Example:
truncate(2024-07-04 12:50.29.25)returns2024-07-04
- Example:
Utility
Utility functions provide helper operations for generating values or performing miscellaneous tasks.
rand(): Returns a random floating-point number between 0.0 (inclusive) and 1.0 (exclusive).- Example:
rand()returns a value like 0.7234 (each evaluation produces a different result).
- Example:
uuid(): Returns a randomly generated UUID (version 4) as a string.- Example:
uuid()returns a value like "123e4567-e89b-12d3-a456-426614174000" (each evaluation produces a different result).
- Example:
Min/Max
Min/Max functions functions allow you to find the smallest and largest value of a set of values.
min(<column1>, <column2>, ...): Returns the minimum value from set of columns or values.- Example:
min(5,1,4)returns1.
- Example:
max(<column1>, <column2>, ...): Get the maximum value from set of columns or values.- Example:
max(5,1,4)returns5.
- Example:
Text
Text functions perform operations on text (char) data. Use a text function to cleanse data, convert data to a different format or case, calculate metrics about the data or do other manipulations.
format(<column>, <format>): Format a value using a specific format. The format can be another column.- Example:
format(1542.0912,'$###0.00')returns$1542.09.
- Example:
parse(<column>,<type>,<format>)- Parses a value from text to specified type.<format>options:..integer,..float,..date,..date_time,..time,..boolean.- Example:
parse(#2024-01-01#,..date,"M/d/yyyy")returns1/1/2024as a text string. - Example:
parse("123.45",..float)returns123.45as a floating point number.
- Example:
text_left(<column>, <length>): Return the left part of a text, with the character count indicated by<length>. The length can be another column.- Example:
text_left(United States,4)returnsUnit.
- Example:
text_right(<column>, <length>): Returns the right part of a text, with the character count indicated by<length>. The length can be another column.- Example:
text_left(United States,4)returnsates.
- Example:
text_length(<column>): Returns the length of a text column.- Example:
text_length(United States)returns13
- Example:
trim(<column>)- Trims whitespace and from both ends.text_replace(<column>, <search>, <replace>,[case_sensitivity]): Replace a part of a text with another text. The search and replace can be another column.[case_sensitivity]options:..Sensitive, ..Insensitive.- Example:
text_replace(United States, States, Kingdom)returnsUnited Kingdom - Example:
text_replace('United States', r/[aeiou]/, '*')uses a regular expression match to returnUn*t*d St*t*s - Example:
text_replace('United States', r/[aeiou]/, '*', ..Insensitive)uses a regular expression match to return*n*t*d St*t*s
- Example:
starts_with(<column>, <value>): Check if a value starts with a specific value. The value can be another column.- Example:
starts_with(Enso Analytics, En)returnsTrue
- Example:
ends_with(<column>, <value>): Check if a value ends with a specific value. The value can be another column.- Example:
ends_with(Enso Analytics, ytics)returnsTrue
- Example:
contains(<column>, <value>,[case_sensitivity]): Check if a value contains a specific value. The value can be another column.[case_sensitivity]options:..Sensitive, ..Insensitive.- Example:
contains(Enso Analytics, nalyt)returnsTrue
- Example:
upper(<column>): Converts a text column to uppercase.lower(<column>): Converts a text column to lowercase.proper(<column>): Converts a text column to proper case. i.e. uppercases the first letter of each word and lowercase the other letters.
Rounding
-
ceil(<column>): Round up to the nearest integer.- Example:
ceil(1.49)returns2
- Example:
-
floor(<column>): Round down to the nearest integer.- Example:
floor(1.49)returns1
- Example:
-
round(<column>, <precision:Integer>,[Rounding_Mode]): Rounds a decimal number to a specified number of decimal places—positive or negative—using symmetric round-half-up by default or banker's rounding if enabled. Rounding_Mode options are..Bankersand..Half_Up...Bankersis often used for rounding currency values, hence 'bankers'. It specifies that ties on rounding are broken by choosing the closest even digit...Half_Uprounds up if the fractional portion is 0.5 or greater. Default is..Half_Upif not specified.- Example:
round([Amount],0,..Bankers)would return the following:
Amount Rounded 2.499 2 2.5 2 1.25 1 2.51 3 3.5 4 - Example:
round([Amount],0,..Half_Up)would return the following:
Amount Rounded 2.499 2 2.5 3 1.25 1 2.51 3 3.5 4 - Example:
-
truncate(<column>): Truncate the decimal part of a number or the time part of a date time.- Example:
truncate(1.49)returns1andtruncate(1.98)returns1.
- Example:
Selections
-
at(<column>, <index:Integer>): Access a value at a specific index. -
get(<column>, <index:Integer>, <if_out_of_bounds>): Access a value at a specific index. -
offset(<column>, <n:Integer>, [fill_with]): Returns the value from the column offset by n rows from the current row. Positive n looks forward (future rows), negative n looks backward (past rows; e.g., -1 for the prior row). The optionalfill_withspecifies behavior at bounds:..Nothing(default, returns null),..Closest_Value(repeats the nearest available value; e.g., for the first row with -1, returns the current row's value), or..Wrap_Around(cycles to the opposite end of the dataset).- Example:
offset([Amount], -1, ..Closest_Value)returns the Amount from the prior row, or the current row's Amount if it's the first row.
- Example:
-
first(<column>): Access the first value in that column. -
last(<column>): Access the last value. -
name(<column>): Access the column name. -
sort(<column>): Sort the values in the column. In-Memory only.- Example:
sort([Amount])
Input
Transaction Amount 1 2.499 2 2.5 3 1.25 Output
Transaction Amount Sorted Amount 1 2.499 1.25 2 2.5 2.499 3 1.25 2.5 - Example:
sort([Amount], ..Descending)
Input
Transaction Amount 1 2.499 2 2.5 3 1.25 Output
Transaction Amount Sorted Amount 1 2.499 2.5 2 2.5 2.499 3 1.25 1.25 - Example:
-
reverse(<column>): Reverse the order of the values in the column. In-Memory only.- Example:
reverse([Transaction])
Input
Transaction Amount 1 2.499 2 2.5 3 1.25 Output
Transaction Amount Reversed Transactions 1 2.499 3 2 2.5 2 3 1.25 1 - Example:
Logical
coalesce(<column1>, <column2>, ...): Return the first non-null value- Example:
coalesce(_Nothing_, Enso)returnsEnso
- Example:
like(<column>, <pattern>): Check if a value matches a SQL pattern. The pattern can be another column.- Example:
like(Enso Analytics, En%)returnsTrue
- Example:
regex_match(<column>, <regex pattern>): Check if a value matches a regular expression pattern. The pattern can be in another column.- Example:
regex_match(Enso Analytics, r/En.*/)returnsTrue
- Example:
is_in(<column>, <value1>, <value2>, ...): Check if a value is in a list of values. All parameters can be columns.- Example:
is_in(CA, WA, OR, CA)returnsTrue
- Example:
contains(<column>, <value>): Check if a value is contained. The value can be another column.- Example:
contains(Enso Analytics, ytics)returnsTrue
- Example:
equals_ignore_case(<column>, <value>): Check if a value is equal to another value ignoring case. The value can be another column.- Example:
equals_ignore_case(Enso, ENSO)returnsTrue
- Example:
is_infinite(<column>): Check if a value is infinite. This condition happens when dividing a non-zero number by zero.- Example:
is_infinite(101/0)returnsTrue
- Example:
is_nan(<column>): Check if a value is NaN.- Example:
is_nan(0/0)returnsTrue
- Example:
is_nothing(<column>): Check if a value is null.- Example:
is_nothing(_Nothing_)returnsTrue
- Example:
is_present(<column>): Check if a value is not null.- Example:
is_present(any text)returnsTrue
- Example:
Constants
pi(): Returns the mathematical constant π, equal to the ratio of a circle circumference to its diameter.e(): Returns the mathematical constant e, the base of the natural logarithm.
Conversion
auto_cast(<column>): Auto detect the value type of a column, and casts the value to this data type.
Values
fill_empty(<column>, <value>): Fill empty values with a specific value (can be another column). Cannot use Previous_Value.- Example:
fill_empty(_Empty_, N/A)returnsN/A
- Example:
fill_nothing(<column>, <value>): Fill null values with a specific value (can be another column). Cannot use Previous_Value.- Example:
fill_nothing(_Nothing_, 0)returns0
- Example:
Metadata
count(<column>): Count the number of non-null values.count_nothing(<column>): Count the number of null values.length(<column>): Get the length of the column (row count).duplicate_count(<column>): Count the number of duplicate values previous to the row.
Limited Functionality
Currently the following functions work but with limited functionality:
take(<column>, <count>)- would allow taking a set of values but would probably evaluate badly.drop(<column>, <count>)- would allow dropping a set of values but would probably evaluate badly.
Examples
The following show how some simple expressions would be evaluated.
-
[FirstName] + ' ' + [LastName]
Concatenates theFirstNameandLastNamecolumns, putting a space betweenFirstNameandLastName. -
[FirstName] = 'John'
Checks if theFirstNamecolumn is equal to'John', creating a True/False column. -
123.456
Creates a constant number column with the value123.456. -
([Age] > 20) AND ([State] IN ('NY', 'CO', 'CA'))
Creates a column that is true if theAgecolumn is greater than 20 and theStatecolumn is in the listNY,COorCA. -
if ([Age] > 20) AND ([State] IN ('NY', 'CO', 'CA')) then 'Target Customer' else 'Disqualify'
Creates a column that contains Target Customer if theAgecolumn is greater than 20 AND theStatecolumn is in the listNY,COorCA. Otherwise it contains Disqualify.
Complexity Limit
Expressions are limited in complexity to make sure that they can be evalauted efficiently. The limit is currently 1024 tokens. If you get an error message like Expression is too complex: 1025 tokens (exceeds 1024). Consider splitting into multiple expressions. then you have exceeded the limit and will need to make it smaller. A token is a piece of an expression and not a character limit. If you find yourself in this situation there is probably a different way in Enso to solve the problem you have.